איך לאחד קבצי Excel עם Pandas: מדריך מעשי ומפורט

למה בכלל לאחד אקסלים? (ולמה דווקא עם Pandas)
בעבודה שלנו, קבצי אקסל מצטברים במהירות: דפי בנק, פקודות יומן, חשבוניות הכנסה, חשבוניות ספקים, כרטסות ועוד. איחוד ידני של הקבצים גוזל זמן, עם סיכוי גבוה לטעויות אנוש וקשה לשחזור. pandas מאפשרת לאחד קבצים בצורה אוטומטית, עקבית ושקופה: הקוד מתועד, ניתן להרצה חוזרת בכל חודש/לקוח, וקל להוסיף בדיקות איכות שמקטינות את הסיכון.
תזכורת קצרה מה זה Pandas 🙂
pandas היא ספריית פייתון לעיבוד נתונים טבלאיים (בדומה ל־Excel אבל בקוד). היא מצטיינת בקריאה/כתיבה של קבצי Excel/CSV, בחיבור טבלאות (merge/concat), בניקוי נתונים, ובחישובים מהירים גם כשיש עשרות/מאות אלפי שורות. היתרון כאן הוא שליטה מוחלטת בלוגיקה ויכולת אוטומציה מלאה (למשל להריץ תהליך איחוד בכל תיקיית לקוח בלחיצה אחת). החיסרון: צריך מעט קוד — אבל בפוסט הזה תהפכו את הקוד לנוח וברור.
אם רוצים לקרוא עוד קצת על Pandas מוזמנים לקרוא את הפוסט שכתבתי בנושא.
שלב 1: הכנת תשתית נוחה להרצת הקוד - הורידו את PyCharm
כדי להתחיל לעבוד בצורה נוחה עם פייתון, מומלץ להוריד את PyCharm – סביבת פיתוח (IDE) פופולרית. נכנסים לאתר הרשמי jetbrains.com/pycharm, לוחצים על כפתור Download, ובוחרים Community (חינמית, מתאימה לרוב הצרכים הבסיסיים, כולל פיתוח בפייתון ועבודה עם ספריות כמו pandas). לאחר ההורדה, מתקינים את התוכנה בלחיצה כפולה על קובץ ההתקנה, ועוברים את שלבי ההתקנה הסטנדרטיים (בחירת תיקיית יעד, קיצורי דרך וכו’). בסיום, אפשר לפתוח פרויקט חדש בפייתון ולהתחיל לכתוב קוד.
שלב 2: התקינו את Python בתוך PyCharm?
אחרי שהתקנתם את PyCharm ופתחתם פרויקט חדש, תתבקשו לבחור או ליצור “Interpreter” – זה בעצם המנוע שיריץ את קוד הפייתון שלכם. אם Python לא מותקן עדיין, PyCharm יזהה את זה אוטומטית ויציע לכם להוריד אותו בלחיצה. פשוט בחרו את האפשרות להוריד ולהתקין Python (רצוי גרסה עדכנית – למשל 3.12), ו-PyCharm יטפל בהכל מאחורי הקלעים. לאחר מכן תראו בפינה התחתונה את גרסת הפייתון שנבחרה – סימן שהכל מוכן להרצת קוד. משם תוכלו לכתוב ולהריץ קוד בצורה חלקה, כולל שימוש ב־pandas וכל ספרייה אחרת.
שלב 3: צרו את התיקיות לפרוייקט:
אני ממליצה על המבנה הבא, אבל כל צורה מסודרת אחרת תעבוד 🙂
project/
├─ data/
│ ├─ raw/ # כאן שמים את כל קבצי המקור (למשל בכל חודש)
│ ├─ reference/ # טבלאות עזר: רשימת לקוחות, מפתח חשבונות
│ └─ processed/ # תוצרי ביניים
├─ outputs/ # קובץ מאוחד סופי, דוחות וכו’
└─ union.py # סקריפט האיחוד הראשי
שלב 4: התקינו את ספריית ה-Pandas
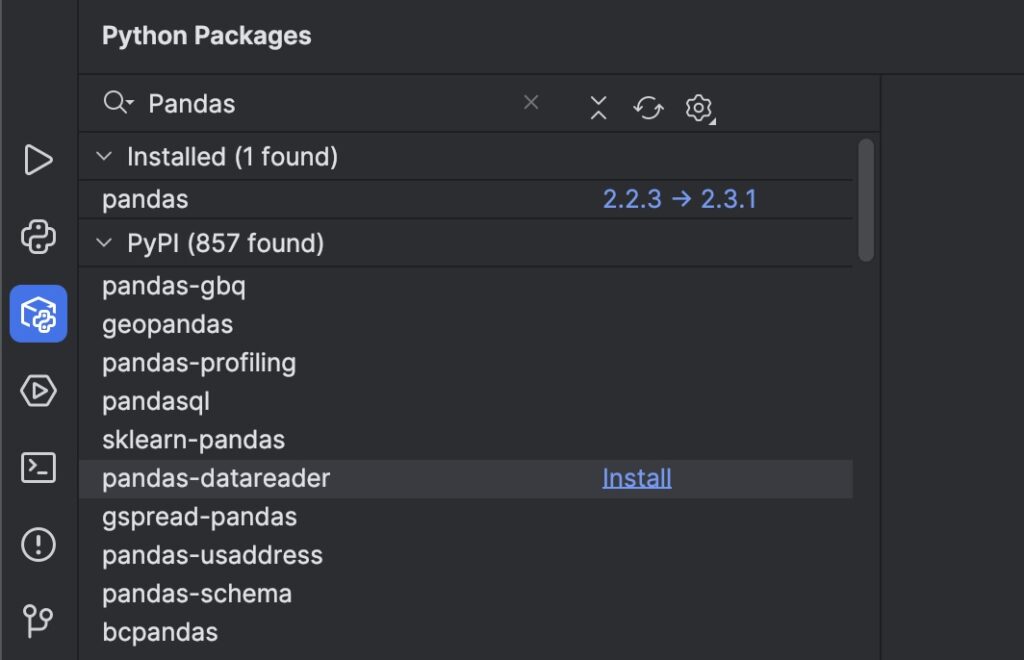
-
בצד שמאל למטה של המסך – גשו ל-Python Packages (האייקון של הקובייה הכחולה).
-
בשורת החיפוש – הקלידו:
pandas. -
ברשימה שתתקבל, תראו את pandas – אם הוא כבר מותקן, תופיע גרסה (כמו אצלך: 2.2.3) ויוצע עדכון לגרסה חדשה יותר (2.3.1).
-
אם pandas לא מותקן – תופיע לידו אפשרות Install. לוחצים על הכפתור להתקנה.
-
אם pandas מותקן וצריך עדכון – לוחצים על החץ עם הגרסאות (כמו בתמונה) ובוחרים לשדרג לגרסה העדכנית.
-
לאחר סיום ההתקנה/העדכון – הספרייה תהיה זמינה לשימוש בפרויקט, ותוכלו לייבא אותה בקוד בעזרת: “import pandas as pd”.
הערה חשובה: בכל קטע קוד שבו נרצה להשתמש ב-Pandas נצטרך להוסיף את השורה הזו. בהתחלה קצת קל לשכוח אבל בסוף אתם תתרגלו 🙂
שלב 5: כתיבת הקוד
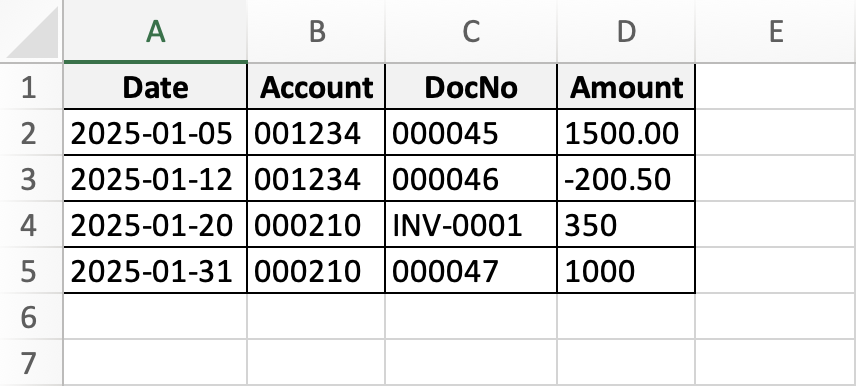
נניח שכל קובץ מכיל גיליון בשם Transactions עם עמודות: Date, Account, DocNo, Amount. נרצה לקרוא את כל הקבצים בתיקייה ולאחד.
כך נראות הטבלאות של ינואר ופברואר:
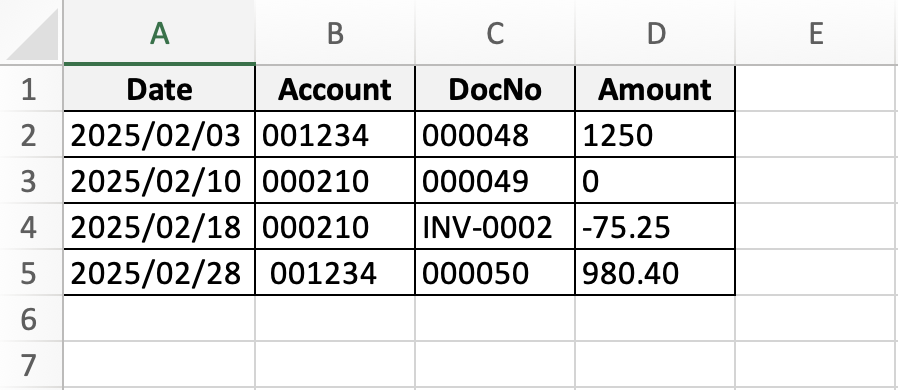
ואלו שלבי כתיבת הקוד:
הגדרת התיקייה:
from pathlib import Path
import pandas as pd
# 1) מגדירים את התיקייה שבה נמצאים הקבצים
folder = Path("data/raw/transactions")
Path("data/raw/transactions") – מפנה לתיקיית המקור.
איתור כל קבצי ה-Excel בתיקייה:
# 2) מאתרים את כל קובצי ה-Excel בעלי סיומת .xlsx
files = list(folder.glob("*.xlsx"))
glob("*.xlsx") – מוצא כל קובץ .xlsx.
פונקציה שקוראת קובץ אחד, מנקה עמודות ומוסיפה עמודת מקור:
# 3) פונקציה שקוראת קובץ אחד, מנקה עמודות ומוסיפה עמודת מקור
def load_one(path: Path) -> pd.DataFrame:
df = pd.read_excel(
path,
sheet_name="Transactions",
dtype={"Account": str, "DocNo": str}, # שומרים אפסים מובילים
parse_dates=["Date"], # ממירים לתאריך אמיתי
engine="openpyxl"
)
# חיווי מאיזה קובץ כל שורה
df["source_file"] = path.name
return df
read_excel(..., dtype={"Account": str}) – מכריח קריאת עמודות כמחרוזת כדי לא לאבד אפסים מובילים (קריטי לקודי חשבון/מע”מ/מספרי חשבונית).
parse_dates=["Date"] – ממיר לעמודת תאריך אמיתית (קל לסנן/לקבץ לפי חודש).
df["source_file"] = path.name – נותן שקיפות: מאיזה קובץ כל שורה הגיעה.
טעינת כל הקבצים לפייתון:
# 4) קוראים את כל הקבצים לפייתון
all_dfs = [load_one(p) for p in files]
איחוד לפי concat:
# 5) מאחדים לרשומה אחת ארוכה
combined = pd.concat(all_dfs, ignore_index=True, sort=False)
pd.concat([...]) – מחבר טבלאות שורה־אחר־שורה.
ניקיון וסידור בסיסי של הדאטה:
# 6) טיפולי ניקוי בסיסיים
combined["Amount"] = pd.to_numeric(combined["Amount"], errors="coerce")
to_numeric(..., errors="coerce") – ממיר Amount למספר; ערכים חשודים הופכים ל־NaN (שאפשר להסיר/לתקן).
שמירת הקובץ לפלט מאוחד:
# 7) שמירה לפלט
combined.to_excel("outputs/transactions_all.xlsx", index=False)
to_excel(..., index=False) – שומר לפלט נקי בלי אינדקס.
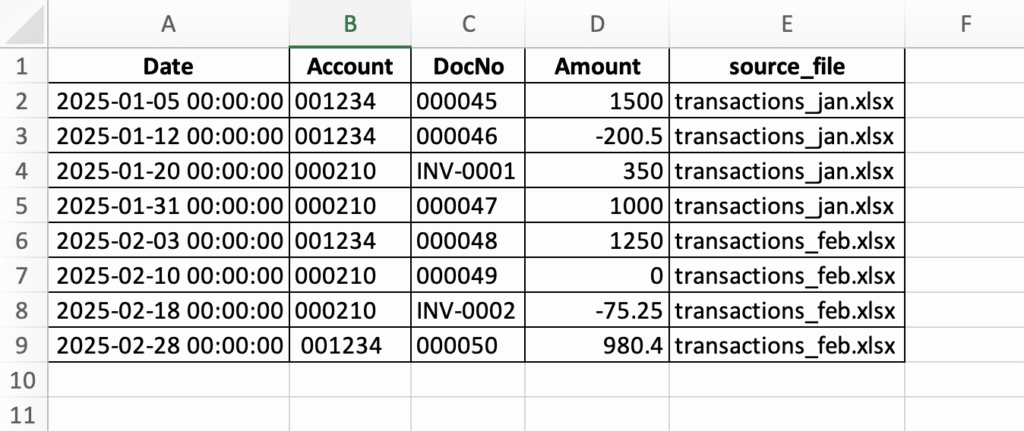
וכך נראת הטבלה המאוחדת שכוללת את המקור שממנו הגיעה כל שורה:
רעיונות לשימושים רלוונטיים
- איחוד קבצי לקוחות שונים כדי לייצר דוח השוואתי חוצה-לקוחות.
יצירת מאגר תנועות יומן שיאפשר ניתוחים ב־pivot.
איחוד של דפי בנק מבנקים שונים.
איחוד רשימות חשבוניות/קבלות.
איחוד של דפי כרטיסי אשראי.
איחוד דוחות מסניפי חברה/מדינות שונות.
איחוד מלאי/מכירות מחנויות שונות.
איחוד דוחות יומיים/שבועיים.
כמה טיפים חשובים
יתרון מרכזי של concat – ברגע שמבנה העמודות זהה, קל מאוד להרחיב את התהליך – פשוט מוסיפים קובץ חדש לתיקייה, מריצים את הקוד, והוא מתווסף אוטומטית לאיחוד.
-
בדיקות! – תמיד תמיד תכינו קובץ בדיקות על הפלט של הקוד שיצרתם על מנת לוודא ששום פרט לא נשמט.
-
ניקוי ואחידות לפני האיחוד – חוסך שעות אחר כך, זה משהו שאפשר ורצוי לעשות ב-Pandas אבל זה כבר למדריך נפרד 🙂
- עבדו בשלבים ושמרו תוצרים ביניים – אל תקפצו ישר לאיחוד הגדול. שמרו גם את הטבלאות באמצע (בתיקיית processed/) כדי שתוכלו לבדוק ולשחזר שלבים בלי להריץ הכל מחדש. זה חוסך זמן דיבוג ומקל להבין איפה משהו “נשבר”.
אז במקום לבזבז שעות על העתק- הדבק בין קבצי אקסל, pandas מאפשרת לכם לאחד הכל בלחיצה – מהר ובקלות. ברגע שתטעמו את הפשטות והעוצמה של הכלי הזה, תגלו איך אפשר להפוך עבודות שגרתיות ומעייפות להזדמנות לצמיחה: יותר זמן לניתוח, יותר שליטה בנתונים, ופחות טעויות אנוש. אחרי שמבינים את הבסיס – מתמכרים לזה.
מכירים את Pandas? מעניין אתכם? תרצו שאוסיף מדריכים פרקטיים? מוזמנים לכתוב לי ולהצטרף לרשימת התפוצה כדי לא לפספס אף מדריך.
כתבות נוספות שיכולות לעניין אותך


חדשות ועדכונים
August 17, 2025
No Comments
מוזמנים להצטרף לקהילה הייעודית שהקמתי ב-Facebook
שם אפשר ללמוד, להתייעץ וכמובן לשתף – כי קהילה זה כוח אדיר!
וכמובן, אם אהבתם, תמיד מוזמנים לשתף את התוכן של הפוסט (:
Copyright © 2025 Gal Bloch